

정구리의 우주정복
Python 웹 크롤링 (Web Crawling) 06. 구글 크롤링 본문
반응형
공부용이라 소스코드 들쭉날쭉할 수 있음 (참고할 사람들은 소스코드 유의깊게보기)
참고는 프로그래머 김플 스튜디오 유튜브
오늘은 맨날 네이버만 크롤링 하다가 구글을 크롤링 해볼거당
야호
웹 크롤링 3번 게시글을 참고하면 이번께 더 쉬울듯
1. 웹 사이트 분석하기
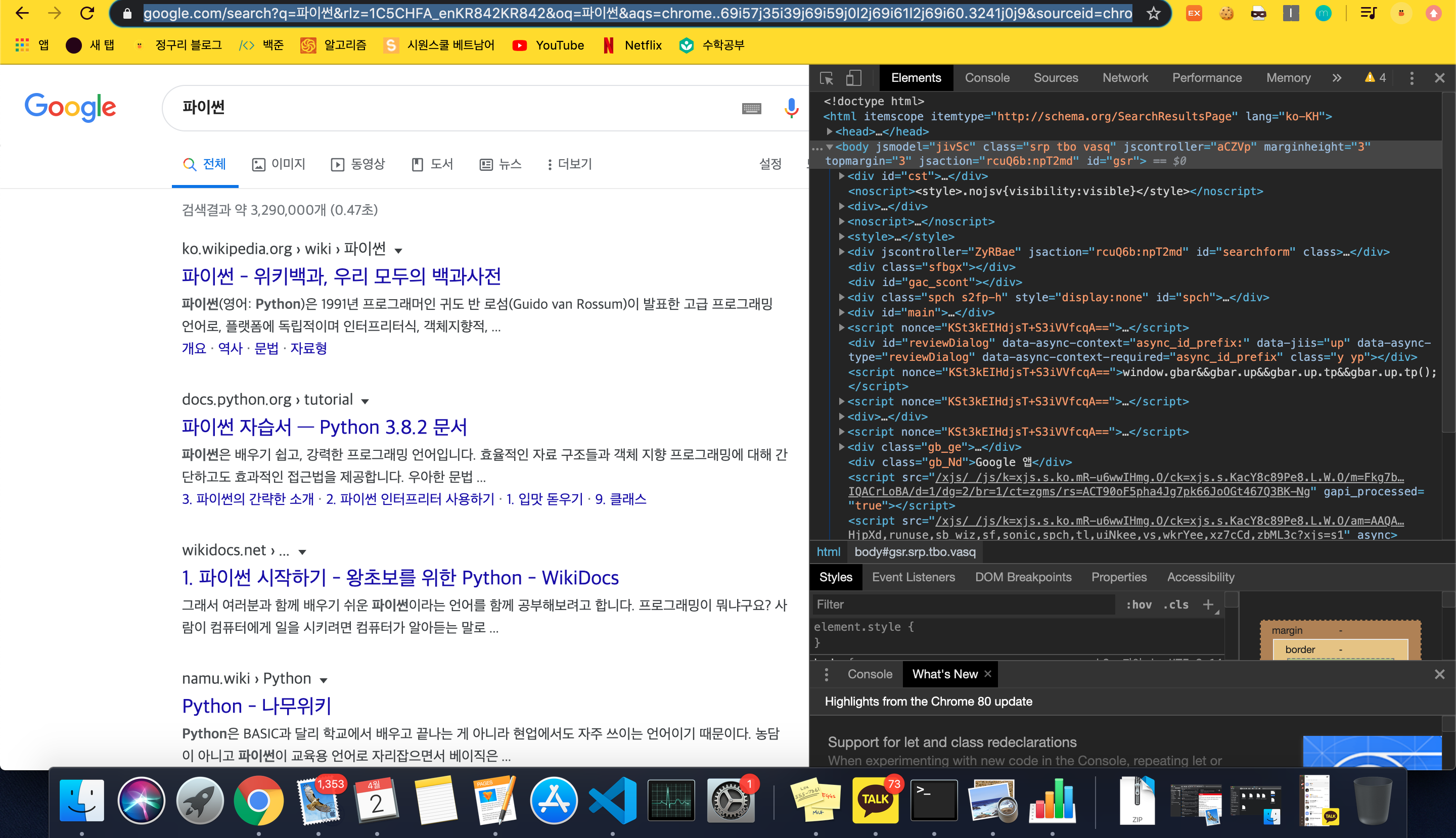
구글에 들어가 파이썬 이라고 검색을 해보면

세상에서 제일 복잡한 url 이 나온다 , 이렇게 복잡하면 분석하기가 힘듬
이때 search?q = '. . . ' 여기 부분이 실질적으로 검색을 하는 부분인데 이 뒷부분을 모두 지우고 검색을 해보쟈

놀랍게도 url 이 바뀌었지만 검색 결과는 똑같다 ! 이렇게 우리는 기본 url 을 얻어버림
html 코드를 분석해보자

div class = r 안에 내가 원하는 href 와 title 을 가지고 있다 따라서 r을 잘 가져오면 될듯
2. 코드 작성
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
from selenium import webdriver
search = input("검색어를 입력하세요 : ")
url = 'https://www.google.com/search?q='
newUrl = url + quote_plus(search)
driver = webdriver.Chrome()
driver.get(newUrl)
html = driver.page_source #열린 페이지 소스 받음
soup = BeautifulSoup(html)
r = soup.select('.r') #클래스 r을 선택 select 로 가져오면 list 형식임
for i in r :
print(i.select_one('.LC20lb.DKV0Md').text) #select 를 안쓰는 이유는 select 를 쓰면 list 로 불러와져서 text 를쓸 수 없다
print(i.a.attrs['href']) #a 태그의 href 속성 가져오기
print()
별다른 설명은 하지 않겠다 !! (웹크롤링 3번 게시글과 이때가지 한 게시글들과 유사함)
select_one 을 사용하는 이유 : select 를 쓰면 list 형태로 가져오게 되는데 list 형태는 text 를 사용하지 못한다
a 태그의 hret 를 가져오려면 i.a.attrs['href'] 이렇게 써주면 됨
이번껀 어렵지 않았다 ! selenium 을 좀 더 많이 사용해봐야지
반응형
'PYTHON > STUDY' 카테고리의 다른 글
| Jupyter Notebook (주피터 노트북 사용법) Python - 주피터 노트북 다운로드 , 주피터 노트북 단축키 (0) | 2020.04.11 |
|---|---|
| VScode 자주쓰는 단축키 모음 (윈도우 , 맥) (0) | 2020.04.05 |
| Python 웹 크롤링 (Web Crawling) 05. CSV 파일 저장 방법 (0) | 2020.04.01 |
| Python 웹크롤링 (Web Crawling) 04. 네이버 검색 결과 여러 페이지 가져오기 (0) | 2020.03.31 |
| Python 웹크롤링 (Web Crawling) 03. 인스타그램 사진 크롤링 'chromedriver' executable needs to be in PATH 오류 해결법 (0) | 2020.03.31 |
'PYTHON/STUDY' Related Articles
more



Comments