
정구리의 우주정복
Python 웹 크롤링 (Web Crawling) 05. CSV 파일 저장 방법 본문
공부용이라 과정이 틀릴수도 있고 위에서 쓴 구문을 아래에선 안 쓸 수도있음 코드 잘 확인하기
참고는 프로그래머 김플 스튜디오 유튜브
오늘은 CSV 파일을 만들어 볼거당
일단 CSV 파일이란 ?
몇가지 필드를 쉼표(,) 로 구분한 텍스트 데이터 및 텍스트 파일 이라고 한다
사실 나도 오늘 첨 들어봄
데이터 수집 -> csv 파일로 저장 하는 방식
이전까지는 그냥 터미널에서 다루었다면 이제는 파일단위로 다루는걸 해볼거다
csv 는 처음이라 강의를 보면서 따라해보도록 할것임 !
오늘의 준비물 : 모바일 네이버
모바일 네이버를 사용하는 이유 : 소스코드가 조금 더 어렵고 pc 에는 없는 view 탭이 있다
그리고 페이지단위가 아니라 자바스크립트로 작성되어 페이지가 따로 없음
오늘은 제목과 링크를 가져올 예정임 !
1. html 분석
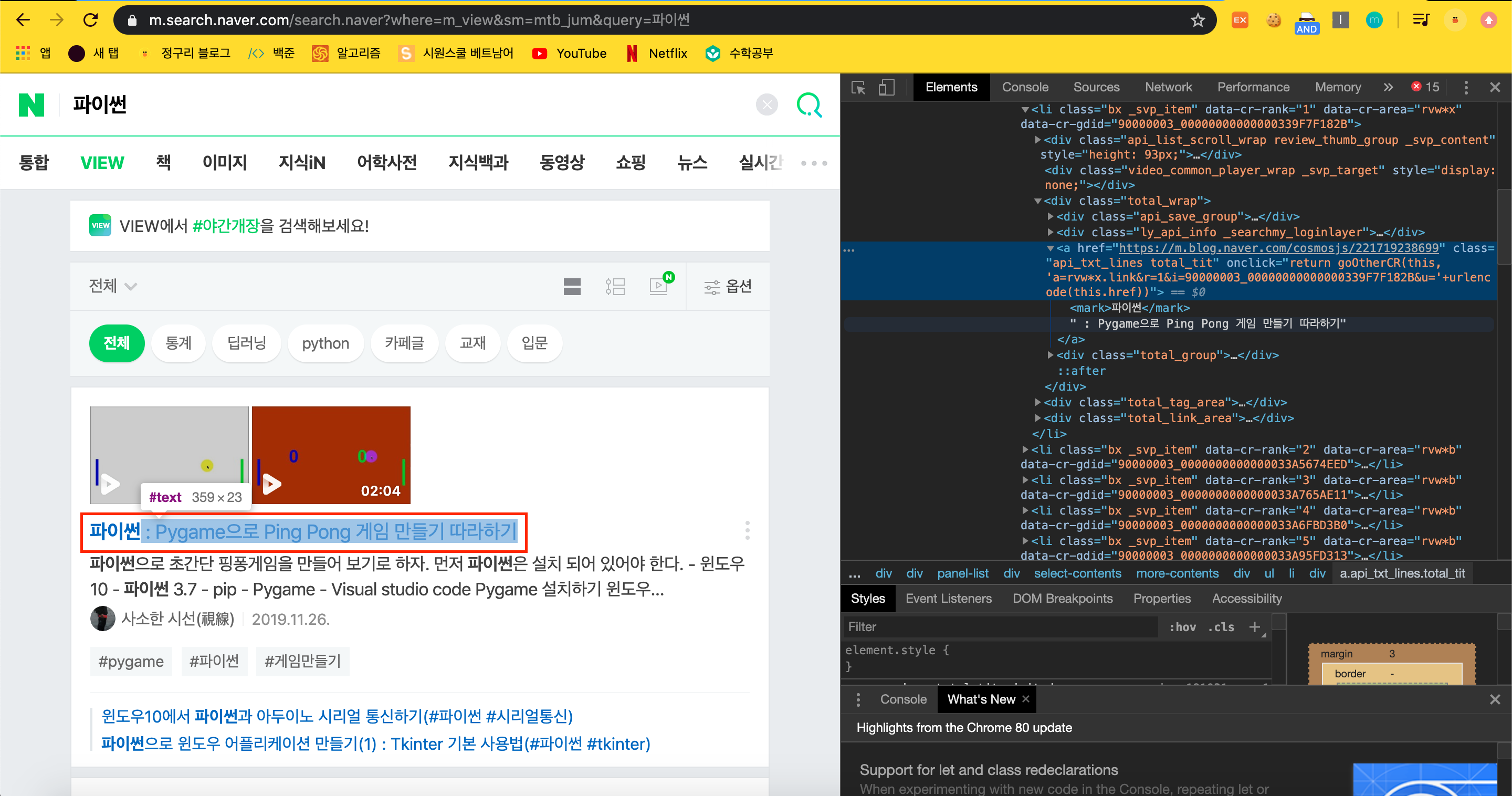
a 태그 안에 href 가 있어서 링크가 들어있고 특이하게 그 안에 mark 태그 안에 제목이 들어가있다
다른 모든 제목들도 같은 형태로 생기고 같은 클래스인 'api_txt_lines total_tit' 를 사용한다
2. html 불러오기
import csv
import ssl
from urllib.request import urlopen
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
context = ssl._create_unverified_context()
#api_txt_lines total_tit
search = input("검색어를 입력하세요 : ")
url = 'https://m.search.naver.com/search.naver?where=m_view&sm=mtb_jum&query=%'
newUrl = url + quote_plus(search)
html = urlopen(newUrl, context=context).read()
soup = BeautifulSoup(html,'html.parser')
total = soup.select('.api_txt_lines.total_tit') #아까 내용이 있던거 싹 가져오기
for i in total :
print(i.text) #call title
print(i.attrs['href']) #call link
print()
다른 게시글에서도 항상 나오던 html 을 불러오는 과정 (별도의 설명은 생략)
새로 배운건 mark 태그 안에 있던 제목은 i.text 로 가져왔다는거 ! 아마 그냥 text 로 취급이 되나 보다
3. csv 저장하기
import csv
import ssl
from urllib.request import urlopen
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
context = ssl._create_unverified_context()
#api_txt_lines total_tit
search = input("검색어를 입력하세요 : ")
url = 'https://m.search.naver.com/search.naver?where=m_view&sm=mtb_jum&query=%'
newUrl = url + quote_plus(search)
html = urlopen(newUrl, context=context).read()
soup = BeautifulSoup(html,'html.parser')
total = soup.select('.api_txt_lines.total_tit') #아까 내용이 있던거 싹 가져오기
searchList = []
for i in total :
temp =[]
temp.append(i.text)
temp.append(i.attrs['href'])
searchList.append(temp) #list 안에 list 가 들어가는 형태
f = open(f'{search}.csv','w',encoding='utf-8',newline='') #파일오픈
csvWriter = csv.writer(f)#열어둔 파일
for i in searchList:
csvWriter.writerow(i)
f.close()
print("완료 !")for 문을 수정하고 그 밑에 파일에 저장하는 거 까지 완성된 소스코드다
일단 searchList = [] 라는 새로운 리스트를 만들어준다
for 문안에 temp =[] 라는 리스트를 만들어주고
temp 안에 제목과 링크주소를 넣어준다
그리고 제목과 링크 주소가 담긴 temp 를 searchList 안에 넣어준다
[ [제목,리스트] , [제목,리스트] ...] 이런식으로 searchList 가 만들어짐
이제 searchList 를 파일에 저장해주는 부분
f=open . . . 부분을 이용해 {search}.csv 파일을 오픈해준다 . 내용을 적어주는거기 때문에 write 를 해주고 (만약에 뒤에 이어서 적고 싶으면 a 를 써주면 된다 )
인코딩은 utf-8 ,
csvWriter 라는 변수를 만들어 csv.write(f) 열어둔 파일을 담아준다
for 문을 searchList로 돌려서 csvWriter.writerow(i) -> i 에 담긴 정보를 write 해준다
다 했으면 f.close() 로 닫아주면 끝

그렇게 해서 만들어진 파일이다 !
제목과 링크가 들어간 csv 파일이 만들어진 걸 확인할 수 있다 !
다음번엔 csv 읽고 쓰기를 좀 더 알아봐야지 !
'PYTHON > STUDY' 카테고리의 다른 글
| VScode 자주쓰는 단축키 모음 (윈도우 , 맥) (0) | 2020.04.05 |
|---|---|
| Python 웹 크롤링 (Web Crawling) 06. 구글 크롤링 (0) | 2020.04.02 |
| Python 웹크롤링 (Web Crawling) 04. 네이버 검색 결과 여러 페이지 가져오기 (0) | 2020.03.31 |
| Python 웹크롤링 (Web Crawling) 03. 인스타그램 사진 크롤링 'chromedriver' executable needs to be in PATH 오류 해결법 (0) | 2020.03.31 |
| Python 웹크롤링 (Web Crawling) 02. 네이버 이미지 검색결과 다운로드 프로그램 ([SSL: CERTIFICATE_VERIFY_FAILED] 오류해결) (0) | 2020.03.30 |


